proFIT.AI — Profile Fit AI: Filtering Ideal Candidates for Recruiters using LinkedIn Profiles and Google BERT
Using contextual learning to avoid limitations of existing profile screening systems can help recruiters and managers to filter candidates for their job requirements.

Screening resumes play a crucial part in hiring the right talent for an organization. However, this process is laborious, so the organizations use automatic screening systems for filtering resumes.

There are many limitations in the current Application Tracking Systems. In fact, 62% of recruiters admit that current profile screening systems overlook some of the qualified candidates. Moreover, current systems are naive because they look for the exact keyword from the job description in resumes for filtering candidates. They are ambiguous as they don’t capture the context of keywords. Candidates can easily trick them by adding or increasing the frequency of important keywords from job descriptions to their resumes.
My goal is to build a robust screening system that avoids the limitations of existing screening systems.
Instead of extracting data from resumes, I crawled candidates’ skills and work experience data from LinkedIn to build my models. LinkedIn has a very strong anti-scraping mechanism which led to different engineering challenges while crawling data. You can also use LinkedIn’s APIs to access data.

I built the above role category tree while crawling data from LinkedIn. I defined broad roles like Engineering and Human Resources. Each broad role is further split into deep roles. For instance, Engineering is split into Data Scientist and Software Engineer, etc. Each profile crawled from LinkedIn is tagged with a broad role and deep role label to perform classification.
I extracted 9243 unique skills from LinkedIn (e.g.: AWS, Social Networking, and Communication, etc) and used these skills as features, endorsements for skills as feature values, and normalized features using Laplace Smoothing. I used skill features to perform multilabel classification using weighted XGBoost and achieved an F2 score of 0.84. I chose the F2 score as a metric because it gives more weight to False Negatives than False Positives. (Recruiters prefer filtering in some irrelevant candidates over filtering out some relevant candidates for the required position)

Once I perform broad role classification, now recruiters will be interested in performing deep role classification for further filtering of candidates. For example, the above plot is the distribution of AWS as a skill among broad roles. However, for deep roles, AWS is an ambiguous feature as there is an overlap among deep roles within Engineering.
So what can be a good feature for developing the deep role classifier?

Let us consider 2 candidates. Candidate 1 is using AWS for Data Processing and Machine Learning. Candidate 2 is using AWS for deploying an application on the cloud. Both candidates use AWS in different ways. While the difference in usage of the skill is ignored by the current ATS systems, it is accurately identified by BERT. This is reflected by the lower cosine similarity score for AWS in different contexts.
I fine-tuned the BERT base uncased pre-trained model on deep role classifier with cross-entropy loss and achieved an F2 score of 0.82.

The above two profiles were overlooked by current ATS systems when recruiters are looking for candidates who use cloud service for data processing and modeling as the exact word ‘AWS’ is absent. But they are captured by the fine-tuned BERT model as these candidates use ‘Azure’ and ‘GCP cloud platform’ for Data Processing and modeling.
proFIT.AI: with better PROfile FIT, comes better PROFIT
Below are the screenshots of input pages for proFIT.AI - a web app developed using Flask that helps recruiters to filter candidates using broad and deep role filtering. Recruiters can select the number of skills, type of skills, and skill proficiency based on their requirements.
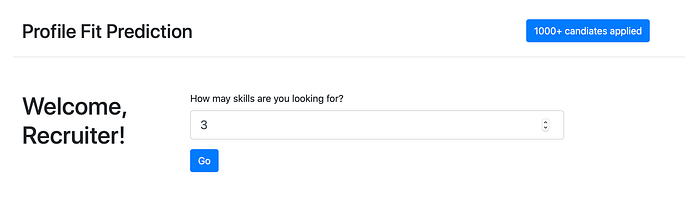
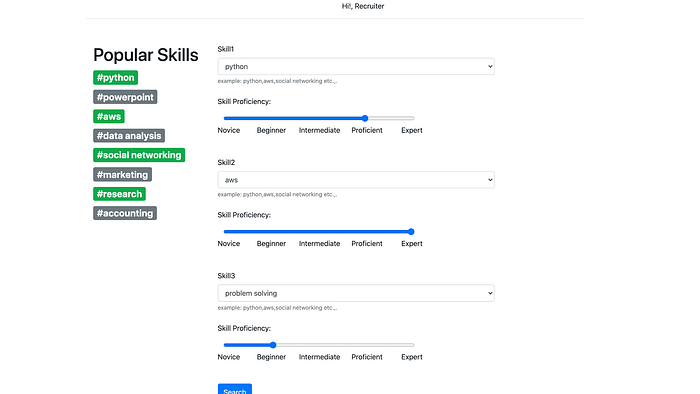
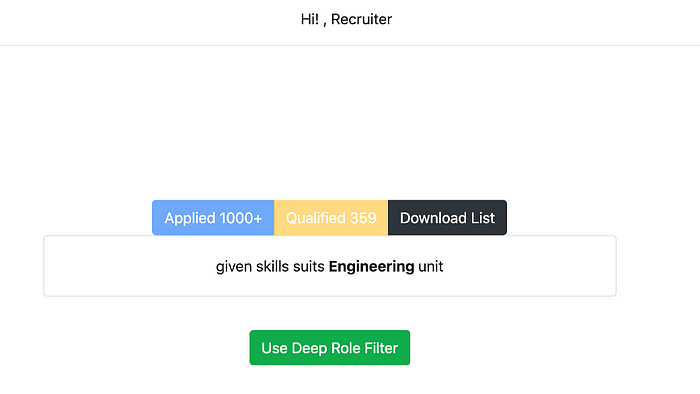
After the recruiter provides inputs, proFIT.AI will perform broad role filtering. In this case, the model predicted that the recruiter is looking for Engineering candidates and it shortlisted 359 candidates.
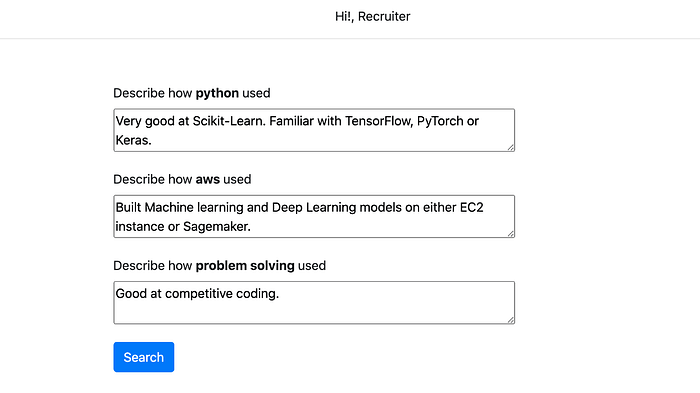

Recruiters can also provide how the skills will be used for the job as shown above and the model further shortlists 137 candidates.
Limitations and Improvements
- Extending the system to candidates who don’t have LinkedIn profiles. I can overcome this limitation by applying OCR (Optical Character Recognition) techniques to extract data from resumes.
- Building a recommendation platform for recruiters and candidates. Candidates need to either provide a LinkedIn profile or resume. Recruiters can filter candidates.
I built proFIT.AI as a 4-week project during my time as an Insight Data Science Fellow. The Insight program is a professional training fellowship that recruits about 30 candidates each term with PhDs or Master’s degrees having experience from various domains.
